The
Curve.
This is the whole project in one plot — accuracy against the compute and the real energy it costs. It is modest on purpose. A clean, dramatic number here would be a red flag; this is the honest shape.
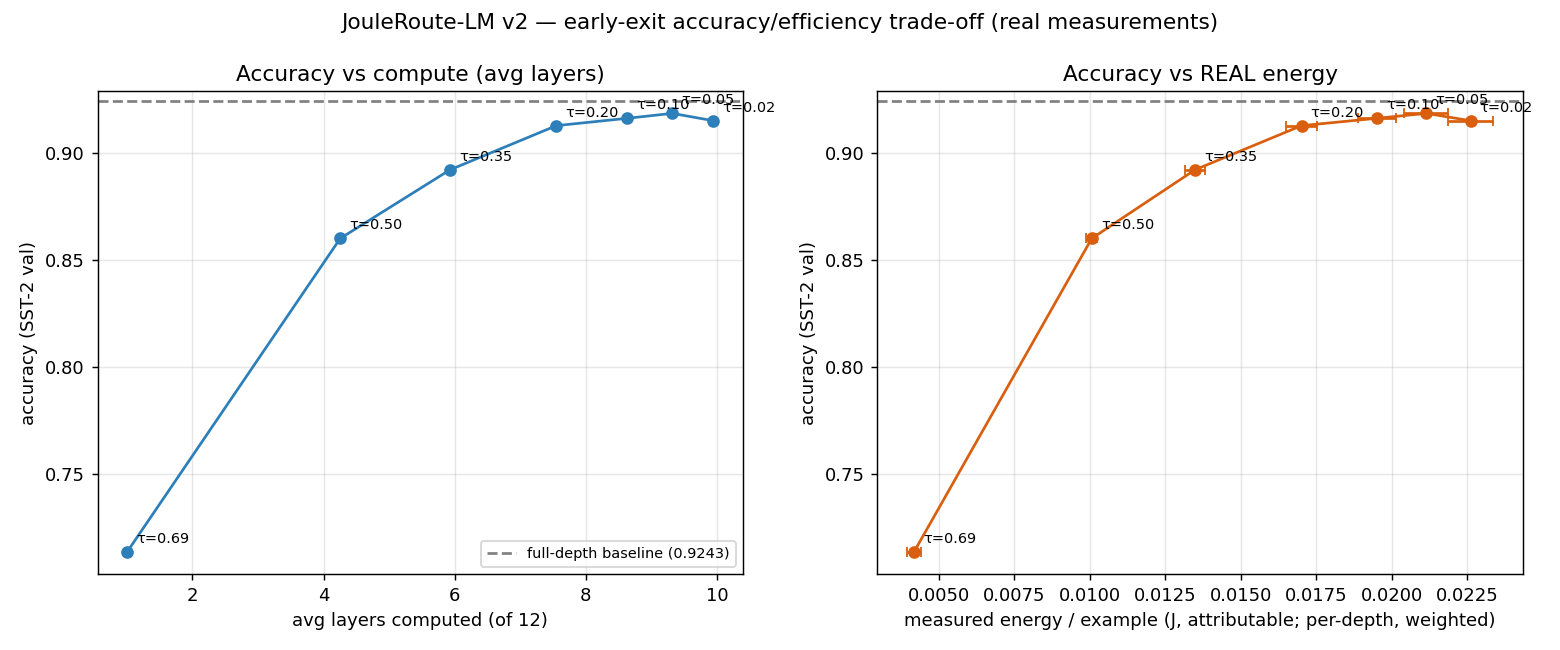
At the sweet-spot threshold (τ = 0.20) the router computes 37% fewer layers and draws ~37% less measured energy per example, while holding 98.8% of the full-depth baseline accuracy (0.913 vs 0.924). The energy is real — it traces to powermetrics logs, not a layer-count estimate.
Across 5 seeds the accuracy change is not statistically significant: paired-permutation p-values stay ≥ 0.30 and the bootstrap 95% CI on Δaccuracy is [−1.15, +0.69] percentage points — it straddles zero. In plain terms: early-exit saved about a third of the compute and energy with no accuracy loss I can actually measure. That is the win.
Notice the energy saved (~37%) is no larger than the layers saved (~37%), and never beats it — embeddings, the layers you still run, and fixed overhead don't vanish, so energy scales sub-linearly with depth. If energy had dropped faster than compute, the measurement would be lying.
Push τ harder and the trade-off appears as it should: by τ = 0.50 you save ~65% of layers but accuracy falls to ~86%; exit at the very first layer and accuracy collapses to ~71%. The knee of the curve — not the extremes — is the operating point.
| Threshold τ | Accuracy | Avg layers | Energy saved |
|---|---|---|---|
| 0.05 | 0.919 | 9.32 | −22% |
| 0.10 | 0.916 | 8.63 | −28% |
| 0.20 | 0.913 | 7.55 | −37% |
| 0.35 | 0.892 | 5.93 | −50% |
| 0.50 | 0.860 | 4.25 | −63% |
| 0.69 | 0.713 | 1.00 | −85% |